Published on: May 29, 2026
A few weeks ago, and after more than a year without any EndBASIC releases, 0.12 showed up out of the blue. If you paid attention to the fine print in that announcement, you knew something big was coming soon. And, as promised, here it is: another brand new major release, 0.13, with a shiny rewritten compiler and VM.
There is a lot to talk about, but before we get to that, here are the must-visit links:
Without further ado, let’s take a peek at the story behind this release.
The performance wall
In January, right after toying with AI to generate EndBASIC demo games and succeeding, I felt I had to fix some long-known performance problems to allow more-impressive demos. Deciding to rewrite code from scratch is never a good idea as the timeless article from Joel Spolsky lectures you, so I started by trying to optimize the old core in-place.
The old core used a hashmap-based symbol table at runtime: the “bytecode” included symbols (functions, subroutines, variables, and arrays) by name and the VM looked those up as such. This is a widely-known no-no for efficient interpreters, so my first attempt at optimization was to transform native function and subroutine calls into array-indexed lookups. This optimization was doable even if it looked a bit out of place. But as soon as I started trying to optimize variable lookups in the same way… well, I ran into trouble. There was no way I could implement this optimization with the previous codebase in any sort of incremental way. I ended up concluding that I had to rewrite the VM from the ground up.
And just like that, I started researching what a good design would look like. Should I use a stack-based VM or a register-based one? How should I structure the registers? Would I need garbage-collection? Could I write the compiler to execute in just one pass? The potential for these thoughts was exciting and I didn’t really plan my next steps: once I had a sketch of how the compiler and VM would look like, I just started coding (because, you know, I like coding by hand). And thus core2 was born.
The new compiler and VM
The core2 implementation is based on a new bytecode designed to look like a “real” processor bytecode: it’s a regular, fixed 32-bit instruction set with 64-bit registers. No more string literals or symbol references by name. No more complex representations that don’t fit in 32 bits.
If you peek through the bytecode.rs file, you’ll find the instruction set defined via a very convenient macro that takes care of implementing each operation’s encoding and decoding. Just as an example, here is how the instruction to add two integer values looks like:
instr!(
Opcode::AddInteger, "ADDI",
make_add_integer, parse_add_integer, format_add_integer,
Register, 0x000000ff, 16, // Destination register.
Register, 0x000000ff, 8, // Left hand side value.
Register, 0x000000ff, 0, // Right hand side value.
);
And then, if we try to compile and disassemble a trivial program like PRINT 4 + 3.5, the compiled program looks like:
0000: LOADI R65, 4 ; 1:7
0001: LOADC R66, 0 ; 1:11
0002: ITOD R65 ; 1:9
0003: ADDD R65, R65, R66 ; 1:9
0004: LOADI R64, 257 ; 1:7
0005: UPCALL 0, R64 ; 1:1, PRINT
0006: EOF ; 0:0
Nothing too surprising here, right? Except maybe for… wait, where is the 3.5? We can see a LOADI R65, 4 that loads the 4 constant in the expression, but where is the equivalent for the float constant? The answer lies in the constant word and the LOADC R66, 0 instruction, which loads “constant number zero”, carrying the 3.5 value, into a register.
I’m bringing this up because, even though the instruction set is pretty standard, the memory model is a bit strange: there is no flat memory space. Instead, the compiler generates a pool of constants and the VM maintains a heap. Both of these are collections of slots where each slot can hold a value of any of the primitive types: a boolean, a double, an integer, a string… or an array of any of these. Memory addresses are indexes into these slots.
Another focus area of this new design has been around the Rust interface of the VM core. The previous implementation relied on async within the VM execution loop to “escape” for cooperative scheduling. In the new design, I’ve explicitly avoided async so that the caller of the VM loop can control when to “yield” to an asynchronous runtime (as is needed in JavaScript). The VM loop now has a first-class concept for “async upcalls”, which is a fancy name for native functions and commands that require servicing by the caller. Taking async out of the common path gave way to a 10-20% speedup in tight loops.
Anyhow. So we have a new VM after 5 months of heads-down development. Was the rewrite worth it?
Performance
To evaluate the performance of core2, I wrote a few benchmarks that target certain VM-level behaviors:
- Arithmetic: Exercises arithmetic operations in a tight loop. No upcalls involved.
- Arrays: Exercises multidimensional arrays and nested loops. No upcalls involved.
- Async upcalls: Exercises executing asynchronous upcalls.
- Branches: Exercises conditional statements, from the simple
IFto the more complexSELECT. No upcalls involved. - User-defined functions: Exercises defining and calling a user-defined function. No upcalls involved.
- Mixed scenario: Exercises user-defined functions, subroutines, and executes various native functions. Represents a more “normal” program.
- Sync upcalls: Exercises executing synchronous upcalls.
All benchmarks were tuned to take roughly 30 seconds when executed with EndBASIC 0.12.1 (the latest release before this one) on my machine—a ThinkStation P710 with 2x Intel(R) Xeon(R) CPU E5-2697 v4 @ 2.30GHz. In this way, the graph below can visually represent a stable “baseline” with a clear depiction of the changes in 0.13.0. I ran the benchmarks with the excellent hyperfine tool until they produced statistically-significant results. And the results are:
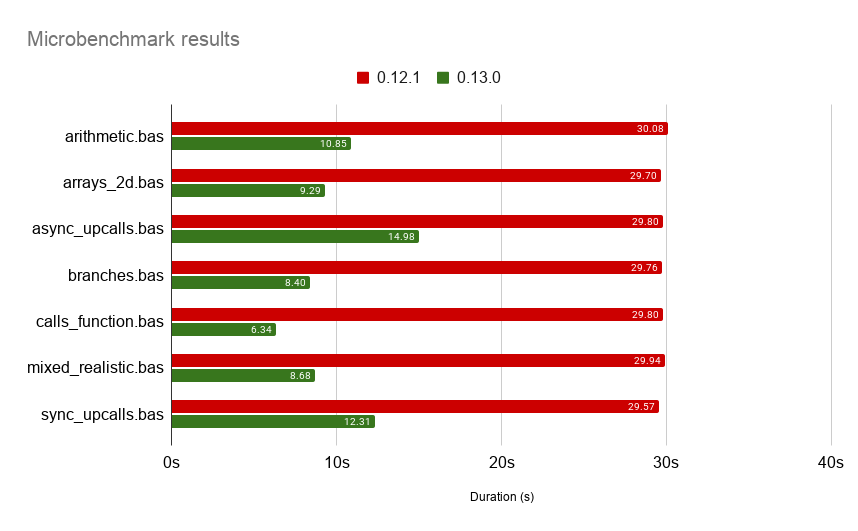
Pretty neat, huh? We’ve got a 4x-5x improvement right off the bat… and these results have been achieved without any sort of targeted optimization just yet! I’m sure there is room to bring those down significantly more, but for now I’m happy with the new state of affairs.
One specific optimization I have not implemented is using tail calls in the VM core to dispatch the following instruction. That’s a well-known optimization that any good VM would implement, but from what I can read, doing this in Rust stable is “tricky”: the optimization may take place in release builds if stars align, but it will not in debug builds. I’d need explicit tail calls to be in Rust stable for this to be possible in a deterministic fashion.
Real performance
But I hear you: it’s too easy to dismiss the above claims because they all come from microbenchmarks specifically designed to showcase the improvements in the VM. So, can we see how this new implementation behaves in real-world programs?
Sure thing! Below is a recording of the Game of Life running with EndBASIC 0.12.1 on the left and with 0.13.0 on the right. I started both instances with a deterministic RANDOMIZE 1 seed and let them run through “completion” until the board stabilized:
In the time 0.13.0 took to compute 1000 generations, 0.12.1 could only compute 671. That’s a 1.49x speedup in the new release. Sure, this is not as impressive as the 4x-5x gains we saw in the microbenchmarks because a program like this has to deal with graphical operations, but still, nothing to scoff at.
Difficulties
Enough about performance though. Let’s switch gears to look at the not-so-fun parts of creating and taking core2 through the finish line.
A major difficulty arose in reimplementing the sheer complexity of the “arguments compiler” that the native functions and commands use to process their arguments in a declarative manner. I originally introduced this abstraction to deal with some self-imposed parsing difficulties, and I’m regretting going the declarative route because of how complex it is (and how it cannot represent certain constructs that BASIC needs). But anyhow… in core2, I rewrote this piece of code from first principles, thinking that I ended up with a better and simpler design than the original. Unfortunately, when I finally tried to port the standard library to the new core, paper-cuts showed up throughout and it was extremely painful to fix them all.
Another difficulty was plugging the new core into the REPL. You see: I designed the core without thinking about REPL-style iteration too much, so by the time I had to put it into practice, it was not possible. I had to retrofit the ability to do some sort of “incremental compilation” so that separate lines entered via the REPL could be compiled on top of existing state, which wasn’t trivial, but is working now. This has had the nice benefit of fixing a major deficiency in the old implementations: user-defined functions and subroutines are now visible across different REPL statements.
And yet another last-minute difficulty was to migrate the EndBOX code to the new EndBASIC APIs. Strictly speaking, this was actually easier to do than you’d imagine even after picking up a new NetBSD baseline thanks to the many breadcrumbs I left for future-me in the past. Re-validating new system images with significant changes in them, however, was tricky—if only because of the need to write actual SD cards and test them out.
The license question
Before concluding, I have to return to the previous article to answer the open question I left you with.
The core2 rewrite has definitely paid dividends in terms of performance, and I feel it provides a nice and solid platform to continue building on. Specifically because of the latter, and because of the thoughts I recently posted on how AI is tainting open source, I have chosen to license the rewritten core under the AGPLv3.
If you go looking at the source code right now, you won’t find a core2. This was the codename for the parallel implementation of the new core, and I kept it separate from the old one until I was confident enough to switch to it. Once that happened, I moved core2 to take core’s place, and thus eliminated the divergence.
Next steps
EndBASIC 0.13 provides the foundations for a much more solid product going forward but, by itself and from your perspective as a user, this release doesn’t do anything other than improve performance. And that’s intentional. 0.12 was a final release right before the core2 switchover, and 0.13 is a release with just the core2 in place. I wanted to isolate this change because I know there will likely be bugs, and because it’s a huge change from a code churn perspective.
The truly exciting stuff lands next. I have some changes queued to bring back a lot of the console improvements I did for the EndBOX into EndBASIC and new features to deal with sprites and sound.
As usual, stay tuned! But for now, go and have fun:
